Etapas do Processamento¶
A solução pynvest-tools abrange a implantação de uma série de recursos AWS que, juntos, comportam uma série de atividades previamente definidas e designadas para um propósito único: disponibilizar dados confiáveis e recorrentemente atualizados contendo indicadores financeiros de ações e fundos imobiliários.
Para que isso seja possível, um total de 6 macro etapas foram desenhadas de modo pontual. Nesta seção, o usuário poderá encontrar detalhes sobre cada uma das etapas de processamento dos recursos do módulo.
Lembrete: arquitetura da solução
Expanda esse bloco sempre que precisar relembrar o desenho de arquitetura de solução.
Clique na imagem para uma melhor visualização dos elementos.
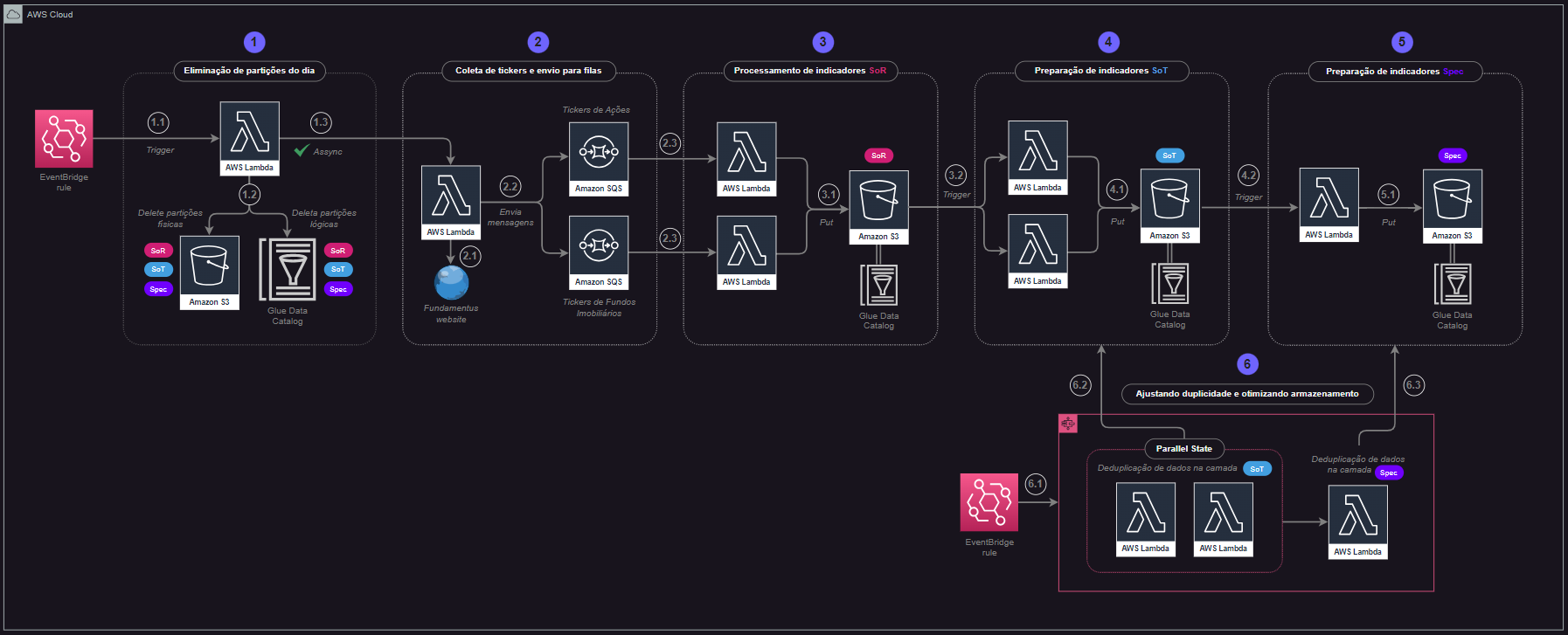
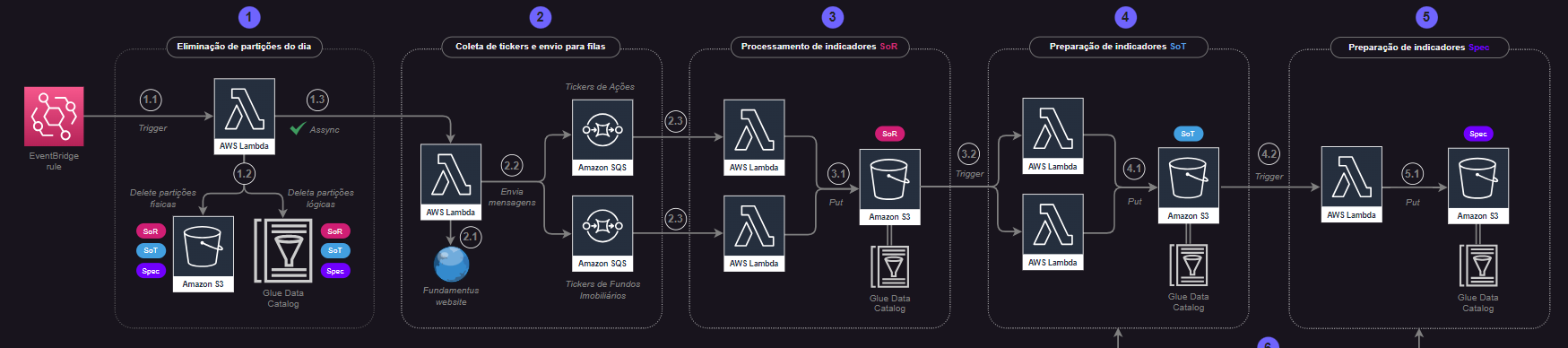
Dica: visando facilitar o detalhamento das etapas, o desenho de arquitetura contempla indicações de sub-etapas em cada macro-etapa do processo. Por exemplo, a etapa 1 definida como "eliminação de partições do dia" contempla os passos 1.1, 1.2 e 1.3 que, de forma simplificada, serão detalhados ao longo desta seção.
Etapa 1: Eliminação das Partições do Dia¶
Clique na imagem para expandir a visualização.

1.1 Um gatilho no Eventbridge agendado para executar todo dia de semana (segunda à sexta) às 18h45m chama a função Lambda pynvest-lambda-check-and-delete-partitions
1.2 A função Lambda citada recebe informações sobre todas as tabelas a serem mapeadas como uma variável de ambiente. Adicionalmente, é criada na função, em tempo de execução, uma variável para armazenar a data atual de processamento através da biblioteca datetime. Dessa forma, um laço de repetição é aplicado à lista de tabelas mapeadas para validar a existência de arquivos físicos no S3 e partições lógicas no Glue Data Catalog relacionadas a data atual de processamento criada. Em caso positivo, ou seja, existem arquivos físicos e partições relacionadas ao dia atual de execução, então a função utiliza métodos do AWS SDK for Pandas para eliminar os arquivos físicos (via awswrangler.s3.delete_objects()) e as partições (via awswrangler.catalog.delete_partitions()) da data de execução do processo de modo a garantir que nenhum registro duplicado será gerado.
1.3 De maneira assíncrona, a função pynvest-lambda-check-and-delete-partitions é responsável por engatilhar uma outra função Lambda para a continuidade do processo.
Etapa 2: Envio de Códigos de Ativos para Fila SQS¶
Clique na imagem para expandir a visualização.
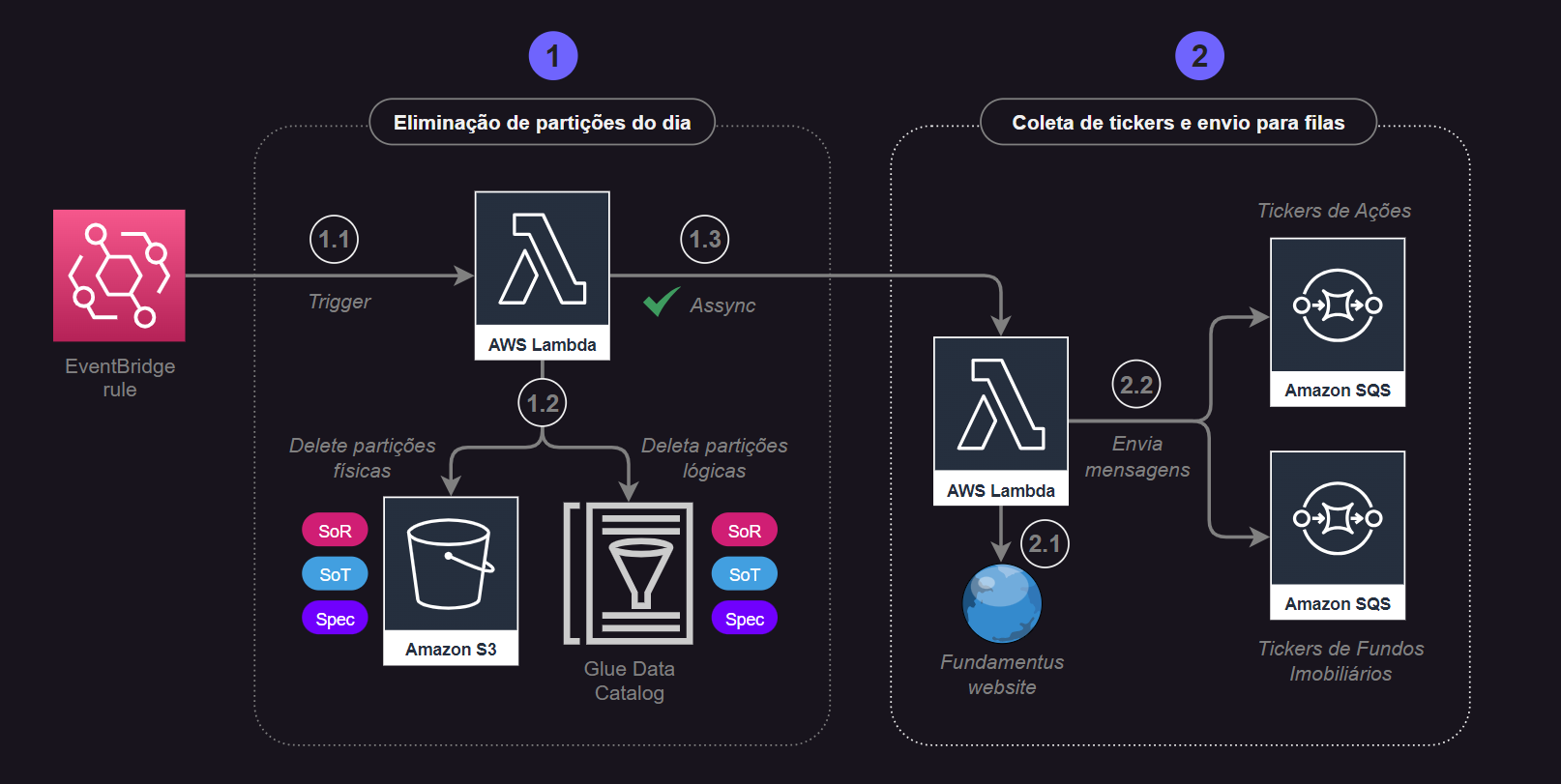
2.1 Na sequência, o processo tem continuidade através da coleta de tickers (códigos) de ativos financeiros (Ações e Fundos Imobiliários) presentes no site Fundamentus. Essa extração é realizada por meio da própria biblioteca pynvest em seu método extracao_tickers_de_ativos() capaz de retornar uma lista de tickers com base em um tipo específico de ativo.
2.2 As listas são então separadas entre Ações e Fundos Imobiliários para, posteriormente, serem alvo de um processo de iteração visando o envio de mensagens para filas específicas no SQS.
Etapa 3: Processamento de Tabelas SoR¶
Clique na imagem para expandir a visualização.
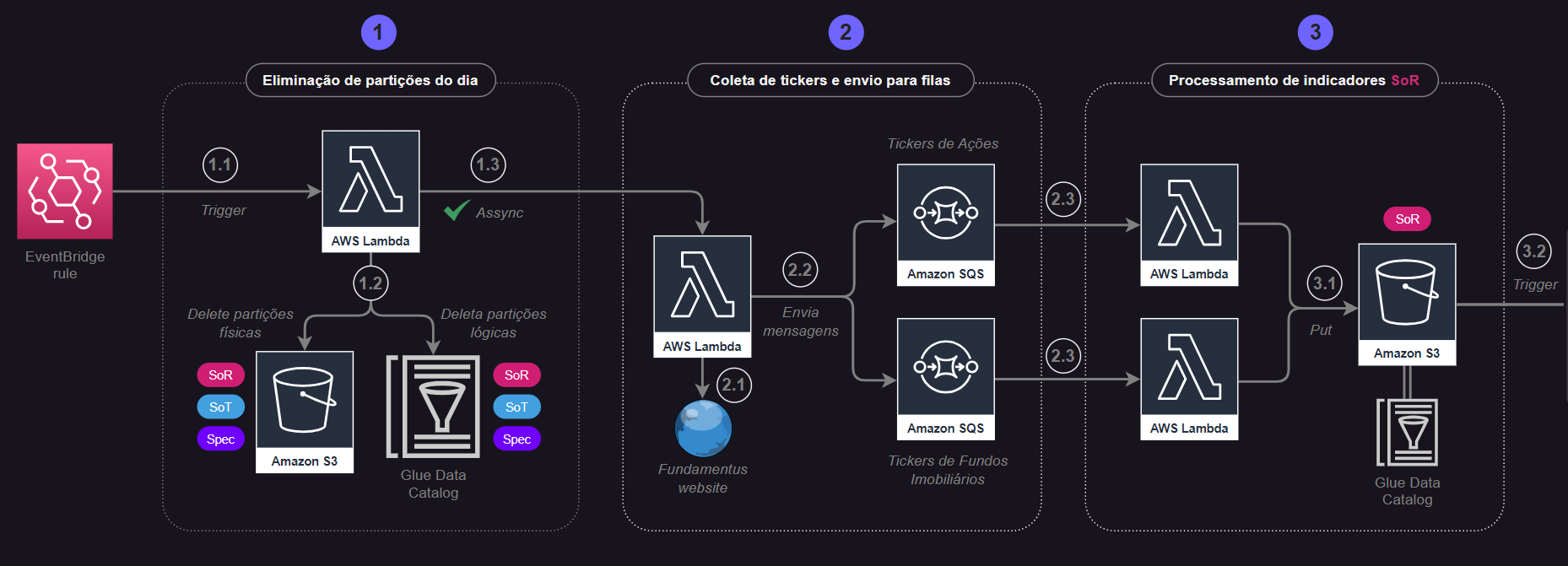
3.1 As filas SQS utilizadas para armazenar tickers de Ações e Fundos Imobiliários, respectivamente, engatilham outras duas funções Lambda. As funções Lambda então recebem os eventos de mensagens recebidas nas filas e, através de um laço de repetição aplicado ao número de mensagens recebidas, coletam as informações de tickers e realizam a extração de indicadores financeiros através do método coleta_indicadores_de_ativo() da biblioteca pynvest. Os indicadores são então obtidos como DataFrames do pandas e escritos no S3 como arquivos parquet no bucket relacionado à camada SoR (dados brutos). A partição física é selecionada como a data de execução do processo. As etapas aqui mencionadas são análogas tanto para indicadores de Ações quanto para Fundos Imobiliários.
3.2 Cada vez que novos arquivos são colocados no S3 (bucket SoR) através da função Lambda acima citada, outras duas Lambdas são acionadas com a missão de ler os arquivos e preparar os dados para serem colocados na camada SoT.
Etapa 4: Processamento de Tabelas SoT¶
Clique na imagem para expandir a visualização.

4.1 Essa etapa é estritamente semelhante à etapa 3.1, com a diferença de que os gatilhos para as funções Lambda de preparação de dados para Ações e FIIs são compostos por eventos no S3 e não em filas SQS. Em suma, toda vez que objetos são colocados no bucket SoR nas locations das tabelas de Ações e FIIs, as respectivas funções Lambda de preparação são acionadas para a leitura dos dados recebidos via eventos, preparação e posterior escrita e catalogação na camada SoT.
4.2 Assim também como na etapa 3.2, cada vez que arquivos são escritos na camada SoT do S3, processos posteriores são engatilhados para a continuidade da solução.
Etapa 5: Processamento de Tabela Spec¶
Clique na imagem para expandir a visualização.
5.1 Mais uma vez, esta etapa se assemelha ao que se pode encontrar em 3.1 e 3.2. A principal diferença se dá pelo fato de estarmos falando de um processo de especialização de dados que utiliza informações de ambas as tabelas SoTs (Ações e FIIs), exigindo assim a existência de uma única função Lambda responsável por ler os arquivos gerados na camada SoT para as tabelas (recebidos via eventos), processar e escrever o resultado em tabela única da camada Spec.
Etapa 6: Deduplicação de Registros¶
Clique na imagem para expandir a visualização.

6.1 Assim como a etapa 1.1 do processo, esta etapa tem seu início através de um gatilho no Eventbridge programado para executar um workflow no Step Functions todo dia de semana (segunda à sexta) às 19h (15 minutos após a execução do gatilho em 1.1). O workflow tem o objetivo único de remover registros duplicados que eventualmente podem surgir durante o processamento dos dados através de eventos nas tabelas das camadas SoT (2 tabelas) e Spec (1 tabela).
6.2 Como uma primeira parte do processo interno do workflow do Step Functions, duas funções Lambda são engatilhadas em paralelo para ler os dados presentes nas tabelas da camada SoT (Ações e FIIs), remover registros duplicados e, por fim, reescrever os dados na mesma camada após o processo de deduplicação.
6.3 Uma vez finalizado o processo de deduplicação de dados na camada SoT, então uma próxima Lambda é chamada com a mesma missão das Lambdas anteriores, porém focada na tabela de ativos presente na camada Spec.
Fim do Processo¶
Com todas as etapas concluídas, o usuário terá a possibilidade de realizar qualquer atividade relacionada à análise de dados de indicadores financeiros, sejam eles brutos (camada SoR), preparados (camada SoT) ou mesmo especializados (camada Spec).